4: How does GPT really work?
Generative Pre-Trained Transformers (GPT) represent a monumental leap in natural language processing (NLP), with their ability to understand and generate coherent text in various contexts. This article explores the evolution of GPT models, their learning paradigms—zero-shot and few-shot learning—the datasets and mechanisms powering their training, and the phenomenon of emergent behavior that has captivated researchers and practitioners alike.
1. Evolution of GPT Models
The GPT series builds on the foundational Transformer architecture introduced in the 2017 paper "Attention is All You Need." This landmark research introduced the self-attention mechanism, allowing models to capture long-range dependencies in text, a significant improvement over earlier methods like recurrent neural networks (RNNs) and long short-term memory networks (LSTMs).
- Transformer (2017): The original Transformer architecture consisted of encoder and decoder blocks. It was primarily developed for machine translation tasks, such as translating English to German or French.
- GPT (2018): Introduced as Generative Pre-Trained Transformer, this model simplified the Transformer architecture by removing the encoder, focusing solely on a decoder for next-word prediction. It relied on unsupervised learning using unlabeled text, pioneering generative pretraining.
- GPT-2 (2019): Scaled up significantly with models ranging from 117 million to 1.5 billion parameters. GPT-2 demonstrated remarkable capabilities in generating text but was still confined to research domains.
- GPT-3 (2020): With a staggering 175 billion parameters, GPT-3 revolutionized NLP by excelling in a range of tasks, including translation, question answering, and text summarization, despite being trained only for next-word prediction.
- GPT-4 (2023): Marked by its superior zero-shot and few-shot learning capabilities, GPT-4 entered the mainstream, becoming a commercially successful model known for its general-purpose applications.
2. Zero-Shot and Few-Shot Learning
GPT models are remarkable for their adaptability, excelling in both zero-shot and few-shot learning scenarios:
- Zero-Shot Learning: The model generalizes to unseen tasks without prior examples. For instance, if prompted with "Translate 'cheese' to French," the model provides "fromage" without additional context or examples.
- Few-Shot Learning: The model leverages a few examples to enhance task performance.
Example: "Sea otter translates to 'loutre de mer.' Peppermint translates to 'menthe poivrée.' Translate 'cheese' to French."
The model uses these supporting examples to deliver a precise output, "fromage."
3. Datasets for GPT Pretraining
A token, for simplicity, can be considered as a word or subword unit. Training with this data scale ensures that the model captures nuanced patterns across multiple contexts and domains.
Training Costs: Pretraining GPT-3 required $4.6 million, reflecting the computational demands of optimizing 175 billion parameters across billions of text samples. This scale of training highlights the resource-intensive nature of large language models.
4. Mechanisms of Pretraining
Next-Word Prediction:
GPT models are trained through next-word prediction, where the model learns to predict the next word in a sentence based on the preceding context. For example:
Input: "The lion is in the..."
Output: "jungle."
This process involves:
- Breaking sentences into input-output pairs during training.
- Example: Input: "The lion is in the." Output: "jungle."
- Using predicted outputs as inputs for subsequent iterations, a mechanism called autoregression.
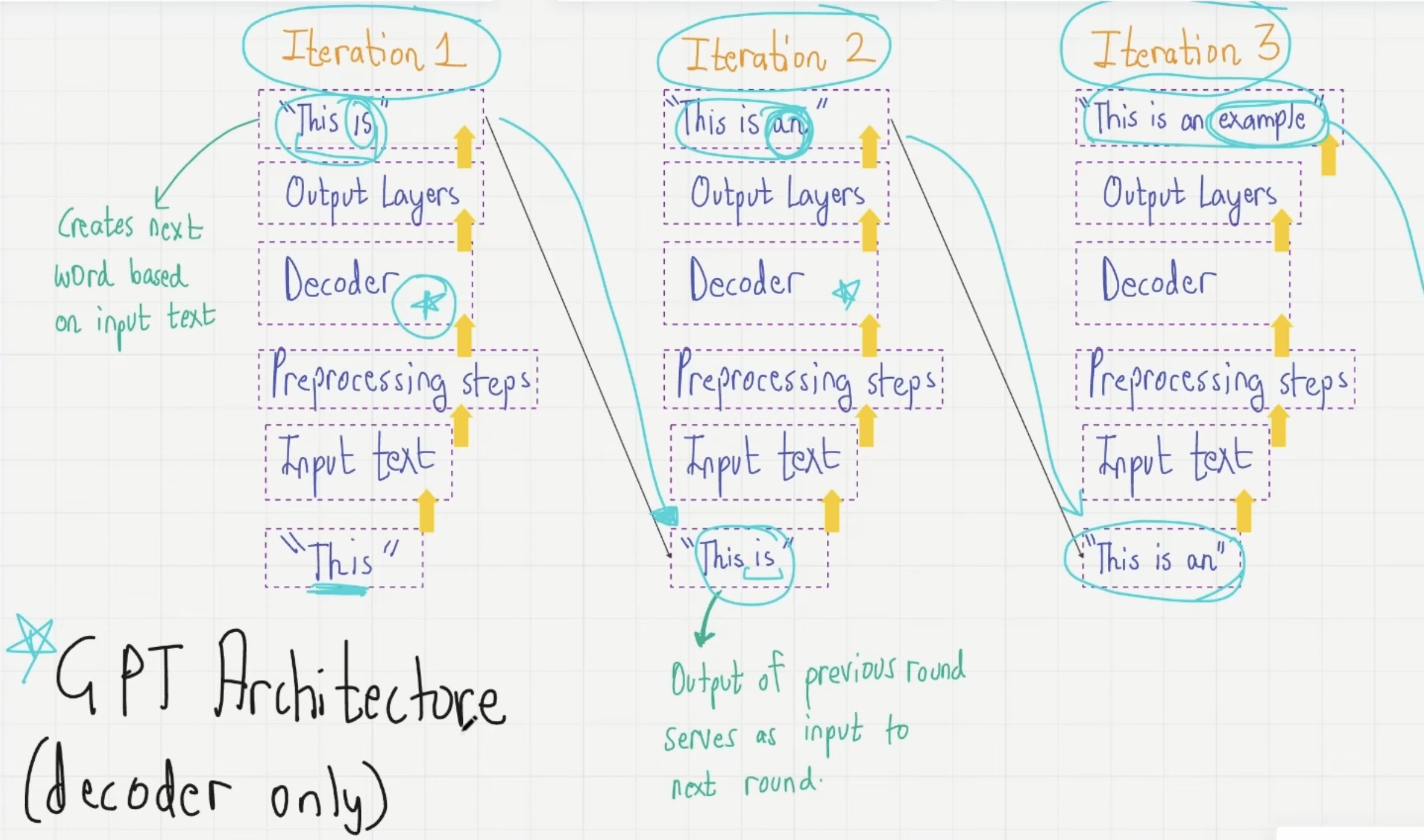
Figure: Illustration of the GPT Architecture focusing on the iterative text generation process.
5. Emergent Behaviors
One of GPT's most fascinating aspects is emergent behavior—its ability to perform tasks it wasn’t explicitly trained for. Despite being designed for next-word prediction, GPT demonstrates remarkable capabilities, such as:
- Translation: Converting "breakfast" to "petit déjeuner" in French.
- Summarization: Condensing articles into concise summaries.
- Creative Writing: Generating poems, stories, or lesson plans.
- Mathematics: Performing arithmetic operations like "523 + 248."
Example of Emergent Behavior:
GPT models can generate multiple-choice questions (MCQs) on topics like gravity. For instance:
Input: "Generate MCQs on gravity."
Output: A set of well-structured questions, despite GPT not being explicitly trained for MCQ generation.
Conclusion
Generative Pre-Trained Transformers have revolutionized NLP, from their origins in the Transformer architecture to the capabilities demonstrated by GPT-4. Their ability to excel in zero-shot and few-shot learning, coupled with emergent behaviors, makes them indispensable tools across industries. As the field advances, the boundaries of what GPT models can achieve continue to expand, setting the stage for even greater innovations in the future.